

A simple round-robin rotation works well when you have a small team with a single service and predictable incident patterns. It breaks down quickly when you have engineers across three continents, multiple services with different criticality levels, a mix of senior and junior responders, and a team that expects fair, sustainable coverage across weekends, holidays, and different time zones.
Complex on-call rotations require deliberate design. The wrong structure leads to night shift overload, coverage gaps, and escalation paths that dead-end under pressure. The right structure means every incident reaches the right person at the right time, on-call responsibilities are shared equitably, and engineers can sustain their on-call duties without burning out.
This guide covers every rotation pattern you need for complex on-call scheduling, how to implement each one, the common challenges that arise, and how to manage them at scale.
The most common rotation is a basic weekly round-robin. As teams grow, this creates problems:
Follow-the-sun scheduling divides on-call coverage across geographic regions, with each region covering hours within their business hours. A team with engineers in North America, Europe, and Asia-Pacific can achieve 24/7 coverage where no engineer is regularly paged in the middle of the night.
Requirements: at least two to three engineers per region, clear 30-60 minute handover windows, automated handover notifications, and a documented cross-timezone escalation path.
Two separate rotations run simultaneously. The primary engineer responds first. If they do not acknowledge within a defined window, the secondary is automatically paged. Particularly effective for teams where junior engineers participate in the primary rotation and need an experienced secondary as a safety net.
Rather than a single flat rotation, service-specific rotations assign different teams to different services. Your payments team has its own rotation. Your infrastructure team has another. This ensures the on-call engineer always has context needed to respond effectively — but multiplies the number of schedules you are managing.
Structures escalation as a series of layers:
Assign on-call responsibility only during specific windows: weekends only, after-hours only, or during deployment windows. Effective for teams transitioning from no on-call coverage to structured coverage.
Teams without a structured cover request process rely on manual manager intervention, which is slow and often leads to the same engineers absorbing all extra on-call load. The solution is a self-service cover request system where engineers can request and approve shift swaps directly, with automatic schedule updates across all integrated systems.
In complex rotations with multiple layers and service-specific teams, routing errors become more common. An alert intended for the payments team reaches infrastructure. The solution is automated routing that reads the current state of all active rotations and routes alerts based on service ownership, current time, and active shift.
Without structured handover communication, incoming engineers start their shift blind. Automated handover notifications summarizing active incidents and system state, delivered at shift change, are essential for complex multi-region rotations.
Tracking on-call load per engineer, measured in pages per week rather than shifts per month, is the right metric for identifying and correcting imbalances before they become retention problems.
1. Map your services and their criticality.
2. Define your geographic coverage requirements.
3. Identify your escalation layers for each service.
4. Configure your scheduling tool to match your rotation structure.
5. Establish handover protocols and automate delivery.
6. Run a four to six week trial and measure pages per engineer, escalation rate, MTTA, and engineer-reported satisfaction.
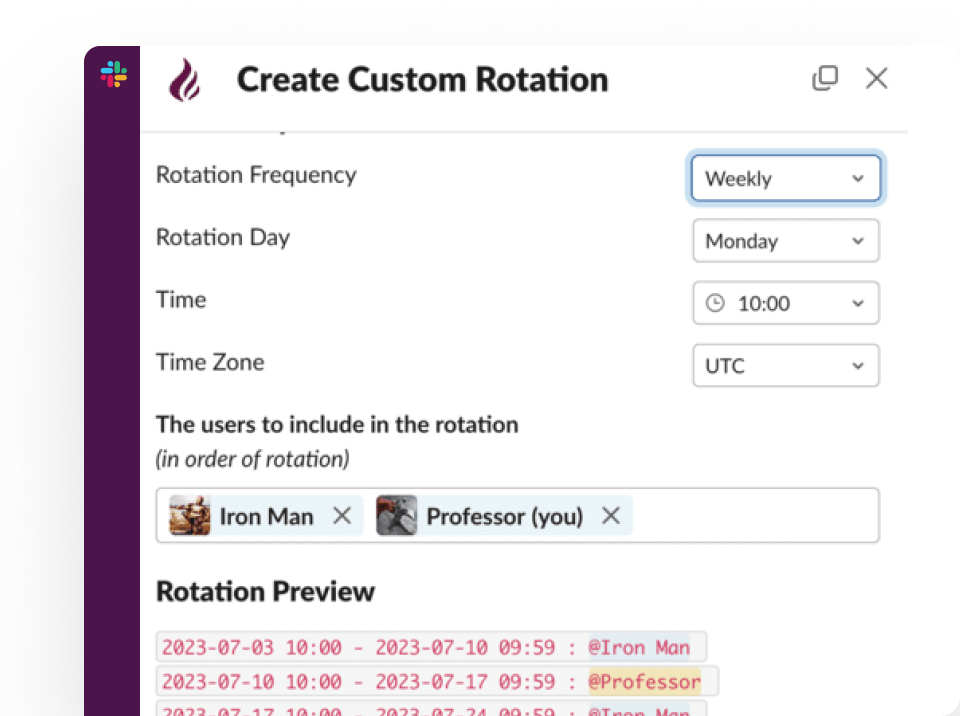
Pagerly is built specifically for the complexity that breaks simpler on-call tools. Rather than forcing your rotation structure into a rigid template, Pagerly gives you the building blocks to implement any pattern your team requires, all managed entirely within Slack.
What Pagerly provides for complex scheduling:
1. Document every rotation structure and its rationale. Complex schedules are hard to remember. Every configuration, escalation path, and handover protocol should be documented and accessible to the whole team.
2. Review and recalibrate quarterly. Use on-call load, MTTA, and escalation rate data to make informed adjustments.
3. Respect labor laws and rest period requirements. Especially for follow-the-sun rotations spanning multiple countries, ensure compliance with local regulations.
4. Build in explicit backup at every layer. Every escalation path should have a defined endpoint that is reachable and accountable.
5. Invest in runbooks for every service. The more complex your rotation, the more important clear runbooks become for engineers arriving at services they may not own daily.
6. Treat on-call load as a team health metric. On-call burnout is one of the leading causes of engineering attrition. Track and address imbalances before they reach a breaking point.
Ready to manage complex on-call rotations without the complexity? Pagerly handles follow-the-sun, layered, and service-specific rotations in Slack, with per-team pricing that stays flat no matter how complex your schedule gets. Get started free
