
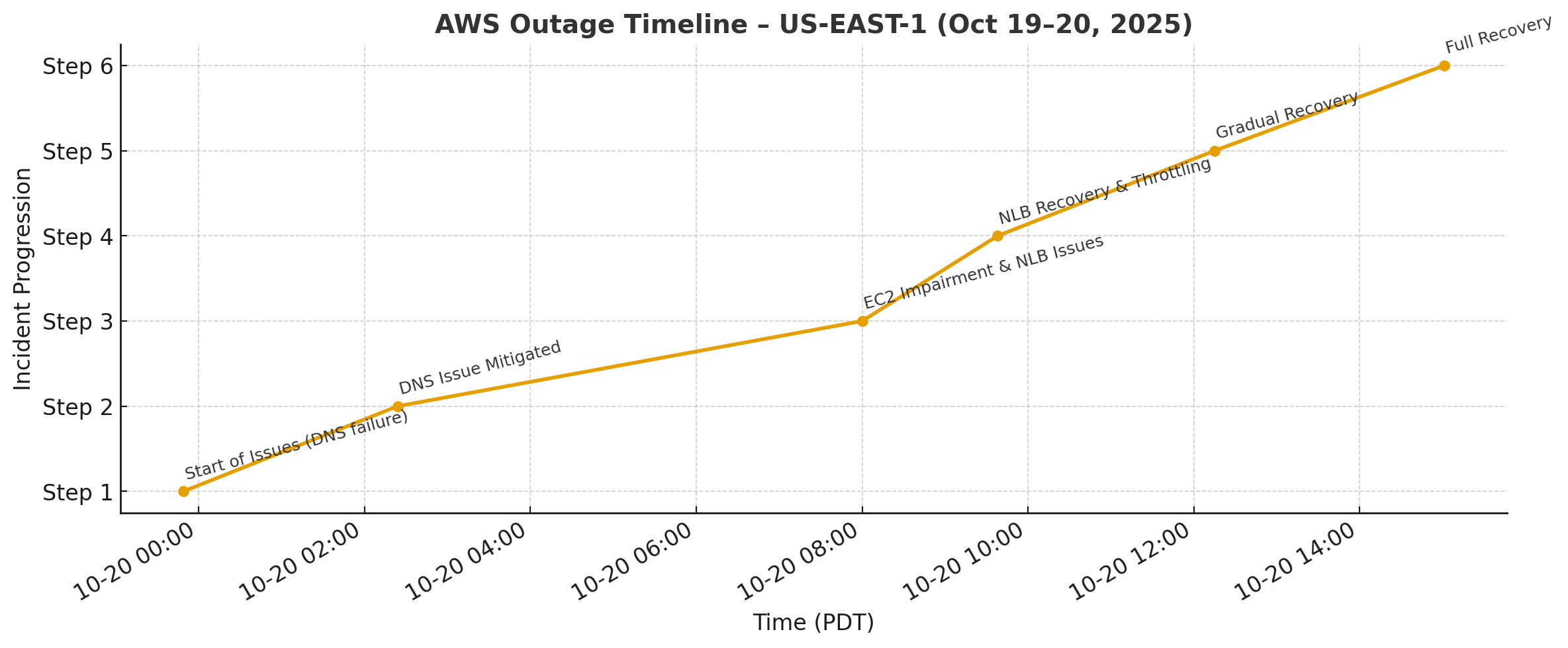
On October 19–20, 2025, AWS US-EAST-1 (N. Virginia) experienced a 15-hour outage triggered by DNS resolution issues in DynamoDB.
This caused cascading failures across 142 AWS services, including critical ones such as EC2, Lambda, S3, DynamoDB, and CloudWatch.
Popular apps like Snapchat, Reddit, Fortnite, Venmo, Duolingo, and Signal were also affected.
Full recovery was achieved by October 20, 3:01 PM PDT.
[RESOLVED] Increased Error Rates and Latencies – AWS US-EAST-1 Region
Incident Link: AWS Service Health Dashboard
During the outage, many widely used consumer applications and platforms experienced downtime or degraded performance, including:
This highlights the far-reaching downstream effects of an AWS regional outage on globally popular applications.
[RESOLVED] Increased Error Rates and Latencies – AWS US-EAST-1 Region
Incident Link - https://health.aws.amazon.com/health/status?path=service-history
The outage was triggered by DNS resolution failures in DynamoDB endpoints for US-EAST-1. This cascaded into:
By Oct 20, 3:01 PM PDT, throttling was lifted and services were fully restored, with a few residual backlogs processed later.
Categories of impacted services:
Popular consumer products disrupted due to this outage:
Snapchat, Reddit, Fortnite, Venmo, Duolingo, Signal
All AWS services have recovered to normal operations.
.jpeg)
Outages like this show how third-party dependencies can ripple through your systems. With Pagerly Monitor, you can:
Stay ahead of outages — let Pagerly help you detect, escalate, and resolve issues faster.